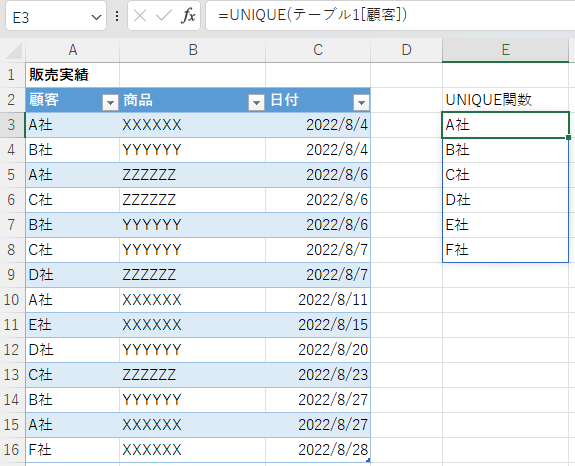
UNIQUE関数は、重複したデータから重複を除いた一意のデータを抽出することができる。
イメージとしては「データ」→「データツール」→「重複の消去」を関数で実施する感じである。
関数を使用することで元データが変わる度に重複消去を実施しなくてもよくなるメリットもある。
UNIQUE関数の使い方
UNIQUE関数の書式は下記である。
UNIQUE関数
=UNIQUE(配列, [列の比較], [指定回数],)
配列:一意の値を抽出する元の範囲、配列。
列に比較(省略可):比較の方法の指定。規定値はFALSE。
FALSE:行を比較し、一意の行を返す。
TRUE:列を比較し、一意の列を返す。
回数指定(省略可):範囲または配列で1回だけ出現する行または列の指定。規定値はFALSE。
FALSE :範囲または配列の重複しないすべての行または列を返す。
TRUE:範囲または配列から1回だけ出現するすべての個別の行または列を返す。
基本的な使い方
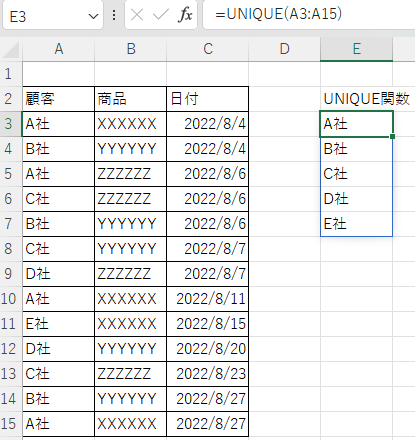
UNIQUE関数は第一引数に配列を指定すると、その配列の一意の値を抽出することができる。
下図のように、売上データの顧客データから一意の顧客データも簡単に作成することができる。
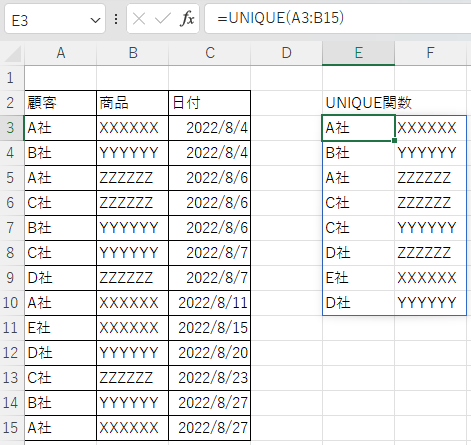
配列は1列でなく2列以上指定することもできる。
下図の場合は顧客と商品の一意の組合せが抽出される。
列の比較の指定
第2引数の列の比較を「TURE」にすると列方向で一意の値を抽出することができる。
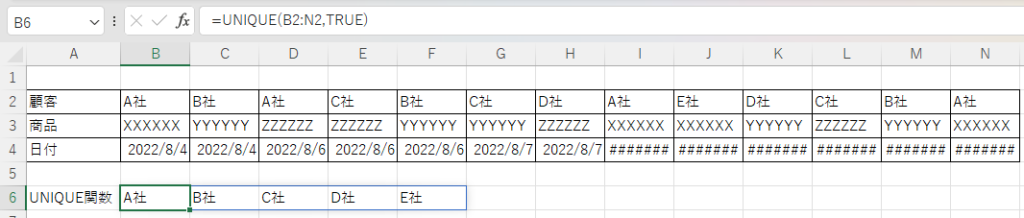
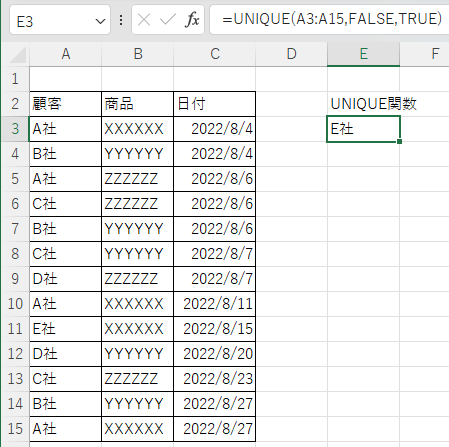
指定回数の指定
第3引数の指定回数を「TURE」にすると配列の中で1回だけ出現するデータを抽出する。
元データにテーブルを使った場合
元データをテーブルにすると、引数が「テーブル名+見出し」となる。
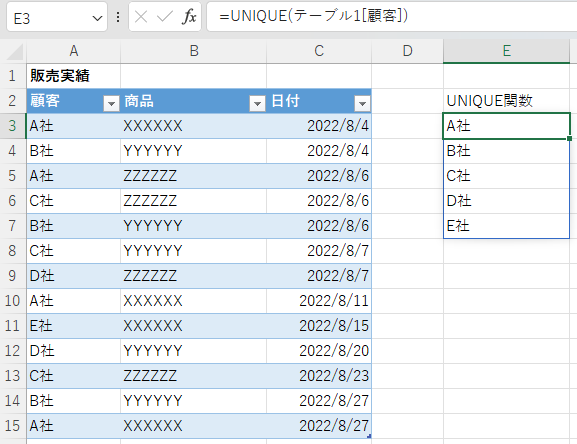
テーブルにF社の売り上げのデータを追加したときは、追加したデータもテーブルのデータとなるため、配列の範囲を変更しなくても自動的に、F社のデータが抽出される。