

TEXTBEFORE関数とTEXTAFTER関数は2022年8月からExcelのMicrosoft365では新関数である。
TEXTBEFORE関数は、文字列の中の指定した文字より前の文字列を抽出できる。
TEXTAFTER関数は、文字列の中の指定した文字より前の文字列を抽出できる。
TEXTBEFORE関数の使い方
TEXTBEFORE関数の書式は下記です。
=TEXTBEFORE(文字列, 区切り文字, [インスタンス番号], [検索方法], [文字列の終端], [見つからないとき])
文字列:対象の文字列
区切り文字:抽出する文字列の起点となる文字
インスタンス番号(省略可):何番目に出現する区切り文字を区切り文字として機能させるかを指定する。マイナスをつけると末尾から数える。規定値は「1」。
検索方法(省略可):大文字と小文字を区別するかを指定する。規定値は「0」
0:大文字と小文字を区別する
1:大文字と小文字を区別しない
文字列の終端(省略可):テキストの末尾を区切り記号として扱うか指定する。規定値は「0」
0:区切り記号をテキストの末尾に一致させない
1:区切り記号をテキストの末尾に一致させる
見つからないとき(省略可):区切り文字が見つからなかった場合に返される値。規定値は「#N/A」
基本的な使い方
TEXTBEFORE関数で電話番号の一部を抽出する。
電話番号の「-」より前の文字列を抽出する例

インスタンス番号を指定しなければ、先頭から検索して最初に見つけた区切り文字よりも前の文字列を抽出する。
この例では、先頭から検索し始めて見つかった「-」より前の「111」を抽出している。
インスタンス番号の指定
第3引数であるインスタンス番号を指定する。
下図はE2セルにカーソルの式を表示している。
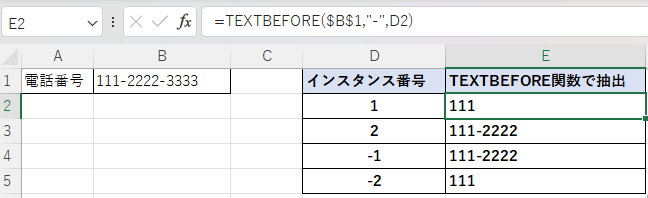
インスタンス番号が「1」は規定値なので、指定しない時と同じように先頭から検索して初めてが現れた区切り文字「ー」よりも前の「111」を抽出している。
インスタンス番号「2」は先頭から検索して2番目に現れた区切り文字「ー」より前の「111-2222」を抽出している。
インスタンス番号にマイナスにした場合は、末尾から検索して現れる区切り文字の番号より前の文字列を抽出している。
検索方法の指定
第4引数の検索方法を指定する。
大文字と小文字の「A」を織り交ぜた文字列を区切り文字「A」としてTEXTBEFORE関数で文字列を抽出する。
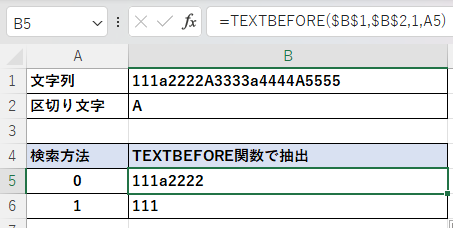
検索方法を「0」とすると区切り文字は大文字と小文字の区別をするため、小文字の「a」は無視され大文字の「A」より前が抽出される。
検索方法を「1」とすると区切り文字は大文字と小文字を区別しなくなるため、最初に現れた小文字の「a」より前が抽出される。
文字列の終端の指定
第5引数は文字列の終端を区切り文字するかどうかを指定します。
下の電話番号は区切り文字「ー」は2個しかありません。終端を区切り文字と指定すると、終端に区切り文字が存在することになります。
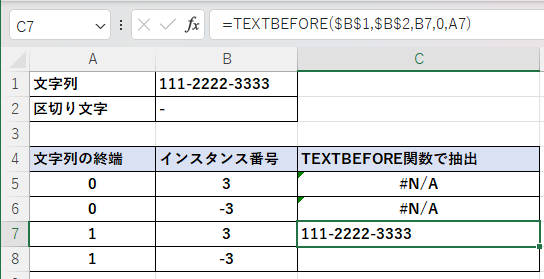
第3引数のインスタンス番号を「3」や「-3」として、文字列の終端を「0」とすると、区切り文字が2個しかないのでエラーになる。
第3引数のインスタンス番号を「3」として、文字列の終端を「1」とすると、文字列の終端を区切り文字として認識させるため、3番目の区切り文字である終端より前(つまり、文字列全て)を抽出する。
第3引数のインスタンス番号を「-3」として、文字列の終端を「1」とすると、末尾から3番目の区切り文字(先頭)よりも前の文字列(空白)を抽出する。
使い道は。。。思い浮かばない。。。
見つからない時の指定
第6引数は、区切り文字が見つからなかった時の表示である。
規定値は「#N/A」となる。
下図では、文字列の中にない区切り文字「A」を指定し、第6引数を“区切り文字が見つかりません!”とする。

区切り文字が見つからなかったので、第6引数で指定した「区切り文字が見つかりません!」が表示される。
TEXTAFTER関数
TEXTAFTER関数は、区切り文字より後ろの文字列を抽出します。
TEXTAFTER関数の書式は下記です。
=TEXTAFTER(文字列, 区切り文字, [インスタンス番号], [検索方法], [文字列の終端], [見つからないとき])
文字列:対象の文字列
区切り文字:抽出する文字列の起点となる文字
インスタンス番号(省略可):何番目に出現する区切り文字を区切り文字として機能させるかを指定する。マイナスをつけると末尾から数える。規定値は「1」。
検索方法(省略可):大文字と小文字を区別するかを指定する。規定値は「0」
0:大文字と小文字を区別する
1:大文字と小文字を区別しない
文字列の終端(省略可):テキストの末尾を区切り記号として扱うか指定する。規定値は「0」
0:区切り記号をテキストの末尾に一致させない
1:区切り記号をテキストの末尾に一致させる
見つからないとき(省略可):区切り文字が見つからなかった場合に返される値。規定値は「#N/A」
基本的な使い方
TEXTBEFORE関数との違いは抽出する文字列が区切り文字より前か後ろのみで使い方は同じになります。
TEXTAFTER関数で電話番号の一部を抽出する。
電話番号の「-」より後ろの文字列を抽出する例

インスタンス番号を指定しなければ、先頭から検索して最初に見つけた区切り文字よりも後ろの文字列を抽出する。
この例では、先頭から検索し始めて見つかった「-」より前の「111」を抽出している。
インスタンス番号の指定
第3引数であるインスタンス番号を指定する。
下図はE3セルにカーソルの式を表示している。
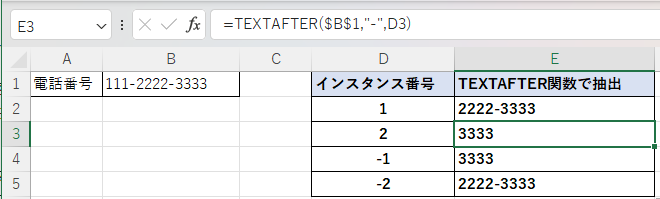
インスタンス番号が「1」は規定値なので、指定しない時と同じように先頭から検索して初めてが現れた区切り文字「ー」よりも後ろの「2222-3333」を抽出している。
インスタンス番号「2」は先頭から検索して2番目に現れた区切り文字「ー」より後ろの「3333」を抽出している。
インスタンス番号にマイナスにした場合は、末尾から検索して現れる区切り文字の番号より後ろの文字列を抽出している。
検索方法の指定
第4引数の検索方法を指定する。
大文字と小文字の「A」を織り交ぜた文字列を区切り文字「A」としてTEXTAFTER関数で文字列を抽出する。
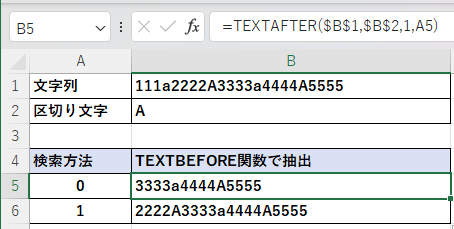
検索方法を「0」とすると区切り文字は大文字と小文字の区別をするため、小文字の「a」は無視され大文字の「A」より後ろが抽出される。
検索方法を「1」とすると区切り文字は大文字と小文字を区別しなくなるため、最初に現れた小文字の「a」より後ろが抽出される。
文字列の終端の指定
第5引数は文字列の終端を区切り文字するかどうかを指定します。
下の電話番号は区切り文字「ー」は2個しかありません。終端を区切り文字と指定すると、終端に区切り文字が存在することになります。
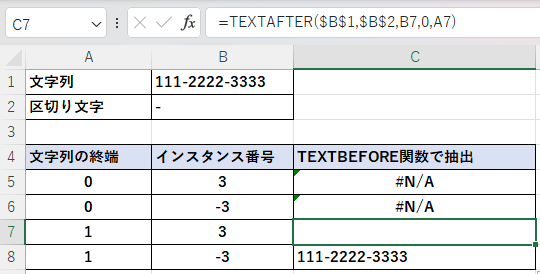
第3引数のインスタンス番号を「3」や「-3」として、文字列の終端を「0」とすると、区切り文字が2個しかないのでエラーになる。
第3引数のインスタンス番号を「3」として、文字列の終端を「1」とすると、文字列の終端を区切り文字として認識させるため、3番目の区切り文字である終端より後ろ(つまり、空白)を抽出する。
第3引数のインスタンス番号を「-3」として、文字列の終端を「1」とすると、末尾から3番目の区切り文字(先頭)よりも後ろの文字列(文字列の全て)を抽出する。
見つからない時の指定
第6引数は、区切り文字が見つからなかった時の表示である。
規定値は「#N/A」となる。
下図では、文字列の中にない区切り文字「A」を指定し、第6引数を“区切り文字が見つかりません!”とする。

区切り文字が見つからなかったので、第6引数で指定した「区切り文字が見つかりません!」が表示される。

